
When I want to save the current state of a pandas DataFrame for “manual consumption”, I often write df.to_excel('foo.xlsx') within my IPython session or Jupyter Notebook. However, the default style does not look pretty and often needs manual adjustments (e.g. column widths) to be usable.
If you want to create custom reports from pandas, you therefore might want to to this styling programmatically. Package openpyxl does this job nicely. Here is a motivational example that shows you the basic ways of its API. First, have some random data:
import pandas as pd
from io import StringIO
df = pd.read_csv(StringIO("""\
alpha beta gamma
2000-01-01 -0.173215 0.119209 -1.044236
2000-01-02 -0.861849 -2.104569 -0.494929
2000-01-03 1.071804 0.721555 -0.706771
2000-01-04 -1.039575 0.271860 -0.424972
2000-01-05 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427
2000-01-07 0.524988 0.404705 0.577046
2000-01-08 -1.715002 -1.039268 -0.370647
"""), sep="\s+", parse_dates=True)
output_filename = 'pandas-to-excel.xlsx'
No customization
Just for comparison, a plain export of the dataframe to the first worksheet:
sheet_name = 'No customization' df.to_excel(output_filename, sheet_name)
Little customisation
As the first column is not readable with the default column width, we increase it slightly. The unit roughly corresponds to Excel’s column width unit. On my machine, the resulting worksheets has a column width of 20.29…
with pd.ExcelWriter(
output_filename,
mode='a', # append; default='w' (overwrite)
engine='openpyxl') as xlsx:
sheet_name = 'Little customization'
df.to_excel(xlsx, sheet_name)
# set index column width
ws = xlsx.sheets[sheet_name]
ws.column_dimensions['A'].width = 21
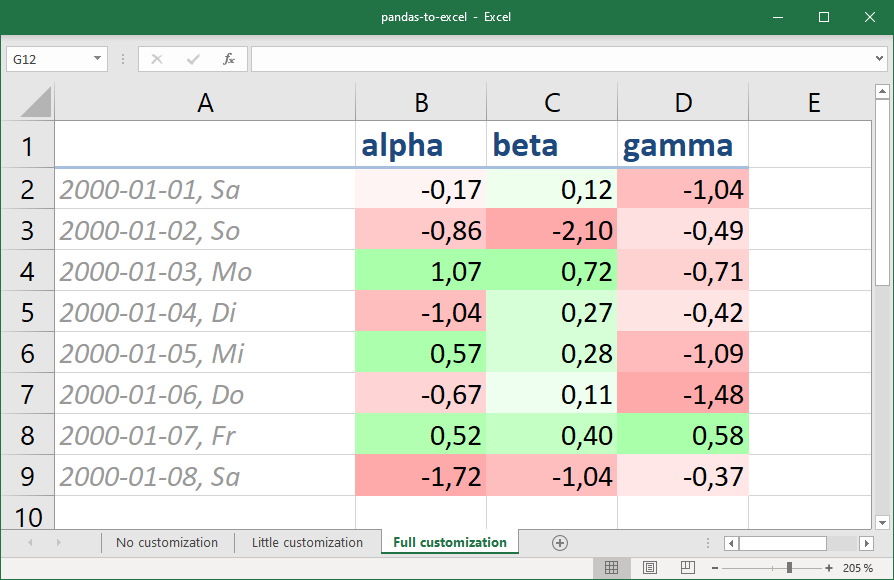
Full customisation
Motivational example of what you can do with some more specifications, namely:
- Conditional formatting, here with a custom color scale using percentiles for lower and upper bound (10%-90%), while the midpoint is defined by value (0 is white). Symbols and color bars are possible as well, of course.
- Number format, using the same syntax as in Excel’s cell properties dialogue. Here, the index column’s date includes the shortened weekday name (Mo-Su).
- Applying a builtin named style by name (Headline 2) to the title row.
- Creating and applying a custom named style (Index Style) including number format, font and alignment.
First, the imports and rule/style definitions:
from openpyxl.formatting.rule import ColorScaleRule
from openpyxl.styles import Alignment, Font, NamedStyle
from openpyxl.utils import get_column_letter
percentile_rule = ColorScaleRule(
start_type='percentile',
start_value=10,
start_color='ffaaaa', # red-ish
mid_type='num',
mid_value=0,
mid_color='ffffff', # white
end_type='percentile',
end_value=90,
end_color='aaffaa') # green-ish
# custom named style for the index
index_style = NamedStyle(
name="Index Style",
number_format='YYYY-MM-DD, DDD',
font=Font(color='999999', italic=True),
alignment=Alignment(horizontal='left'))
# pass keyword args as dictionary
writer_args = {
'path': output_filename,
'mode': 'a',
'engine': 'openpyxl'}
With that, the actual writing looks like this:
with pd.ExcelWriter(**writer_args) as xlsx:
sheet_name = 'Full customization'
df.to_excel(xlsx, sheet_name)
ws = xlsx.sheets[sheet_name]
# cell ranges
index_column = 'A'
value_cells = 'B2:{col}{row}'.format(
col=get_column_letter(ws.max_column),
row=ws.max_row)
title_row = '1'
# index column width
ws.column_dimensions[index_column].width = 21
# color all value cells
ws.conditional_formatting.add(value_cells,
percentile_rule)
# for general styling, one has to iterate over
# all cells individually
for row in ws[value_cells]:
for cell in row:
cell.number_format = '0.00'
# builtin or named styles can be applied by using
# the style object or their name (shown below)
for cell in ws[index_column]:
cell.style = index_style
# style title row last, so that headline style
# wins over index style in top-left cell A1
for cell in ws[title_row]:
cell.style = 'Headline 2'
If you want the above in one script, try my gist pandas-to-excel.py. It creates a single Excel file with the three appropriately named spreadsheets.